WebScraper教程

WebScraper教程
DreamCollector一、什么是WebScraper?
WebScraper是一款网站数据提取工具,它类似于爬虫,但使用门槛较低,适用于轻度的数据爬取。 Web Scraper主要以谷歌扩展插件的形式存在,允许用户无需编写复杂的Python爬虫代码,即可轻松地从网站上提取所需的数据。这种工具能够模拟人类的网页浏览行为,帮助用户快速、高效地收集网页上的数据。
二、安装教程(需科学上网)
您可以从Chrome 商店或 Firefox 浏览器附加组件安装扩展程序。安装后,您应该重新启动浏览器以确保扩展程序已完全加载。如果您不想重新启动浏览器,请仅在安装后创建的选项卡中使用该扩展程序。
三、使用教程
安装好后可通过快捷键打开浏览器开发者工具,更多详情使用也可参考官方文档
Windows、Linux :
Ctrl+Shift+I或者F12苹果:
Cmd+Opt+I
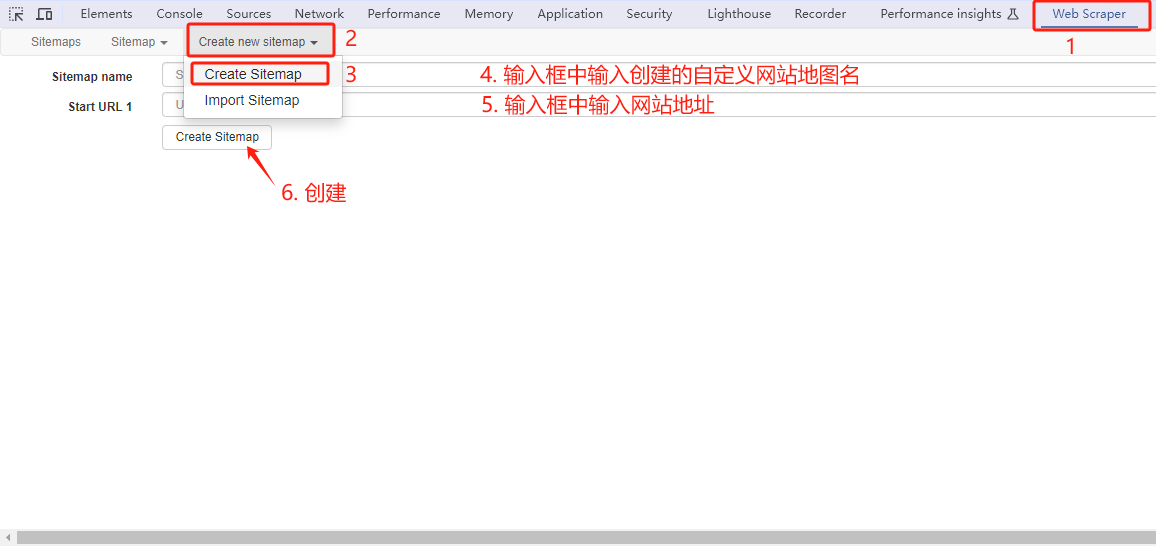
1. 创建网站地图
对于类似这样的链接使用范围URL也可使用[开始数字-结束数字]
- URL:
http://example.com/page/[1-3]http://example.com/page/1http://example.com/page/2http://example.com/page/3
若是增量范围URL也可使用[开始数字-结束数字:步长]
- URL:
http://example.com/page/[0-20:10]http://example.com/page/0http://example.com/page/10http://example.com/page/20
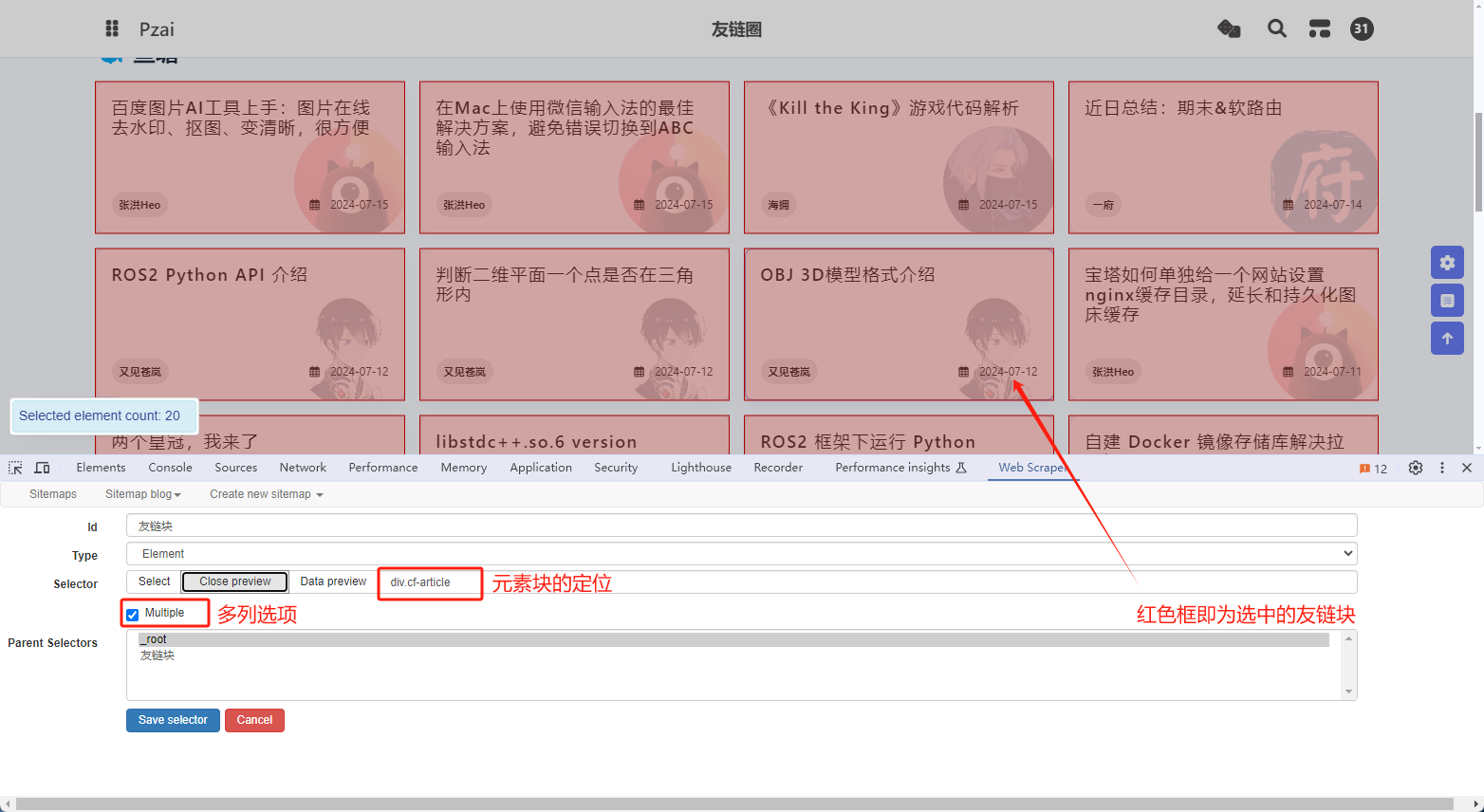
2. 添加父选择器
这里以抓取友链圈的文章为例子,添加需要抓取的友链块元素
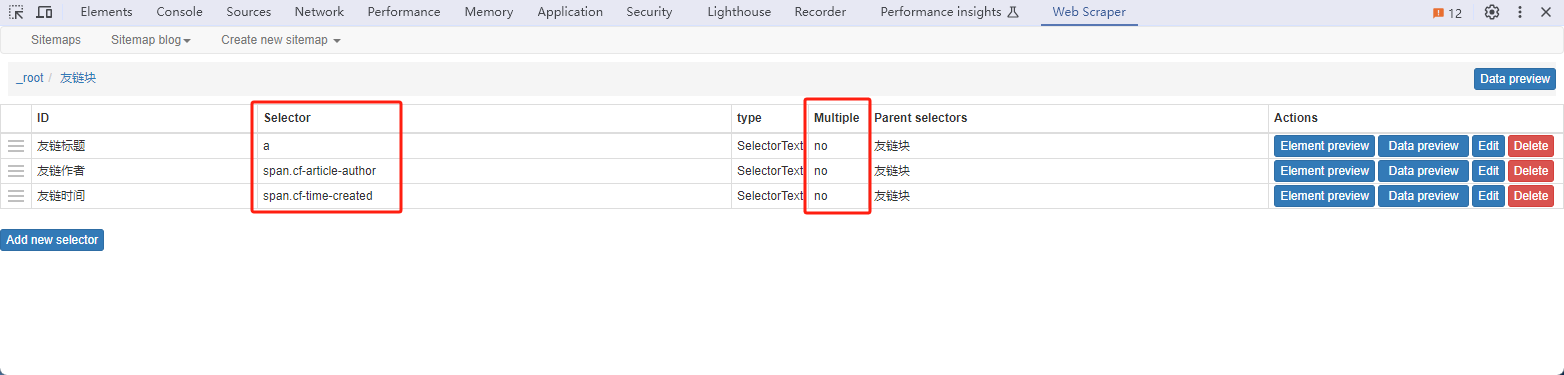
3. 添加子选择器
之前选中了块元素,后续只需在多个块元素中选择想要爬取的元素即可,前面父类勾选了Multiple后续的子类就无需再勾选了
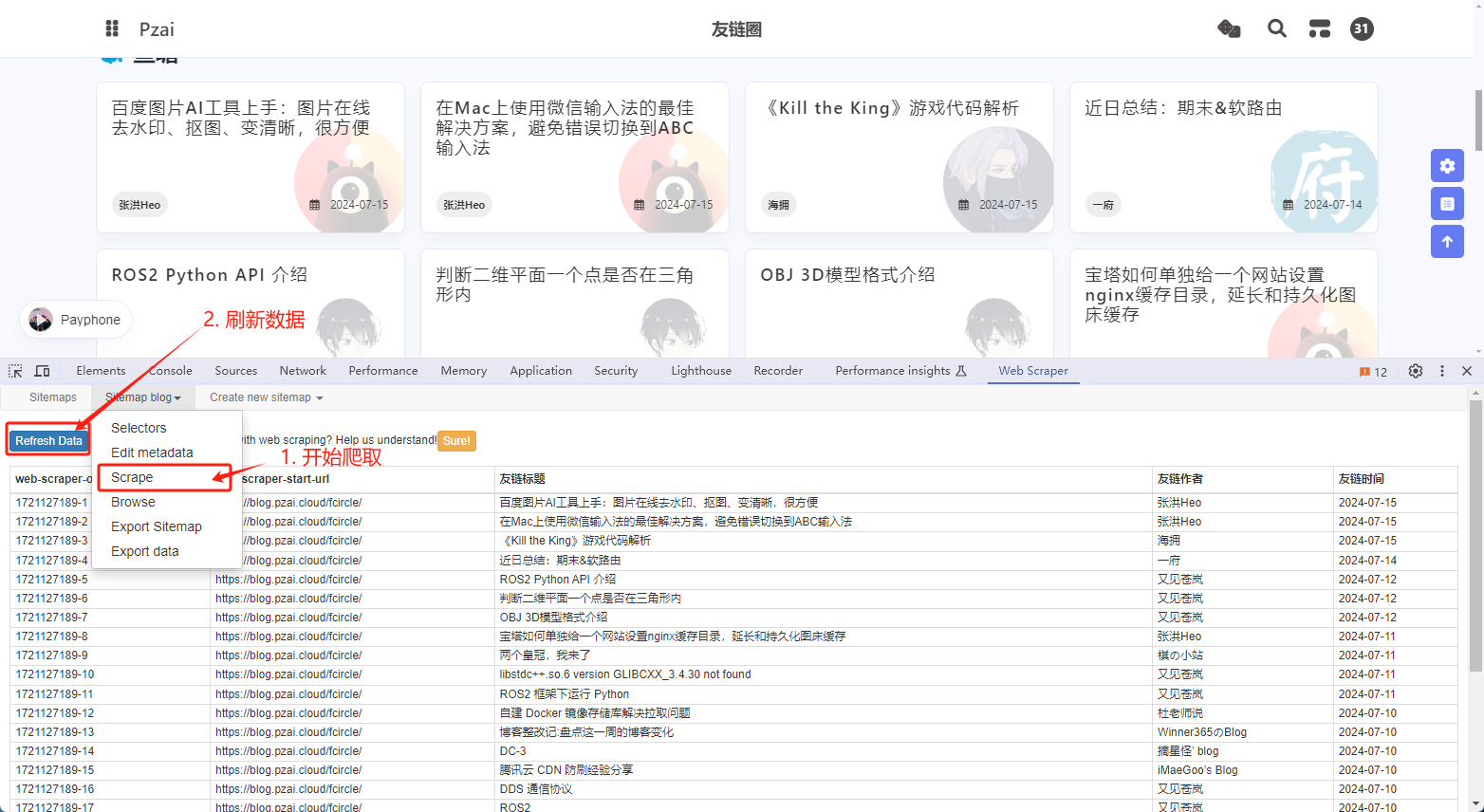
4. 开始爬取
5. 节点总览
flowchart LR
_root --> 友链块
友链块 --> 友链标题
友链块 --> 友链作者
友链块 --> 友链时间
四、高级技巧
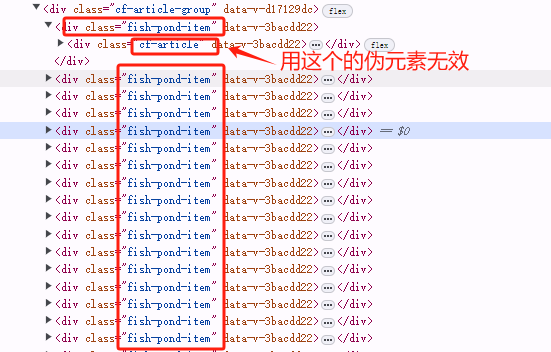
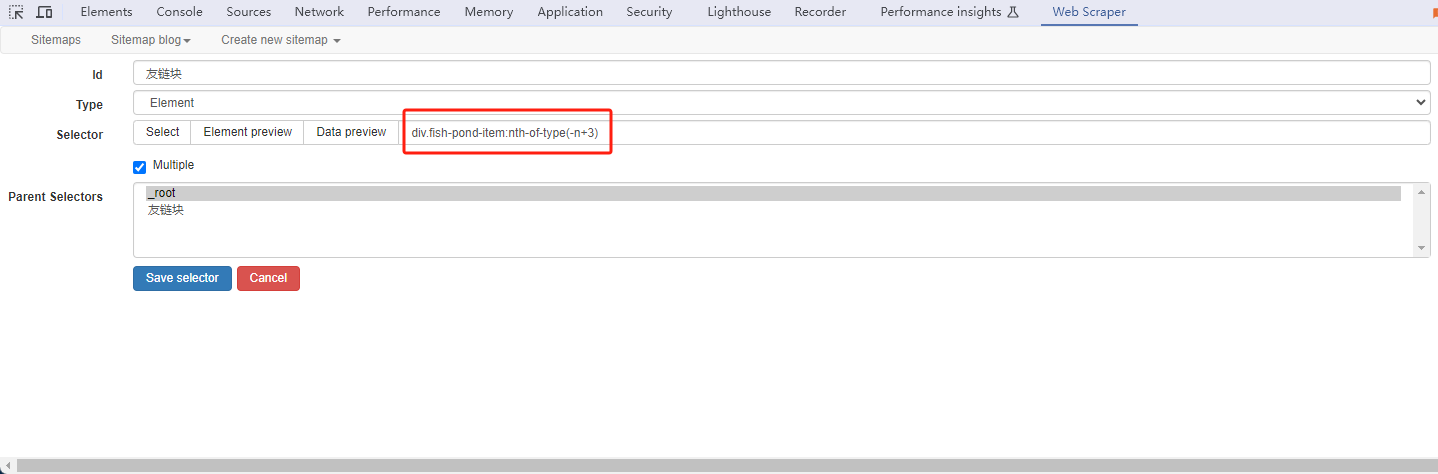
1. 只抓前N条数据
由于抓取一般都是有多少就抓多少,直到数据没有,可以通过数据编号伪元素进行控制抓取的条数,在Selector 后加
:nth-of-type(-n+10)即为前10条数据,并且还需要是多个一级父类元素后加才有效


评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果

公告
欢迎来看我的博客鸭~ 

退出:esc
方向控制: ←↑→
射击:Space
轰炸:B
